Research Articles

Overcoming Sparse Coverage in Nanopore Methylation Sequencing: Strategies, Tools, and Clinical Applications
Sparse data coverage presents a significant yet addressable challenge in nanopore-based DNA methylation sequencing, impacting the reliability of epigenetic profiling for research and clinical diagnostics.
Overcoming Small Effect Size Challenges: Optimized Experimental Design for Robust Epigenomic Research
Epigenomic studies frequently grapple with small-magnitude effect sizes, which complicate detection and interpretation in environmental health, aging, and disease research[citation:2][citation:5].
Machine Learning for Epigenomic Data Mining: A Comprehensive Guide from Data to Clinical Translation
This article provides a targeted overview for researchers, scientists, and drug development professionals on applying machine learning (ML) to epigenomic data mining.
Beyond the Single Layer: How Coupled Matrix Factorization Unlocks Integrated Insights from Multi-Omics Data
Integrating diverse omics datasets is critical for a systems-level understanding of biology but is challenged by high dimensionality, heterogeneity, and noise.
Decoding Functional Insights: A Practical Guide to GO Term Analysis of Epigenomic Datasets for Biomedical Research
This article provides a comprehensive guide to the functional analysis of epigenomic datasets using Gene Ontology (GO) terms, tailored for researchers and drug development professionals.
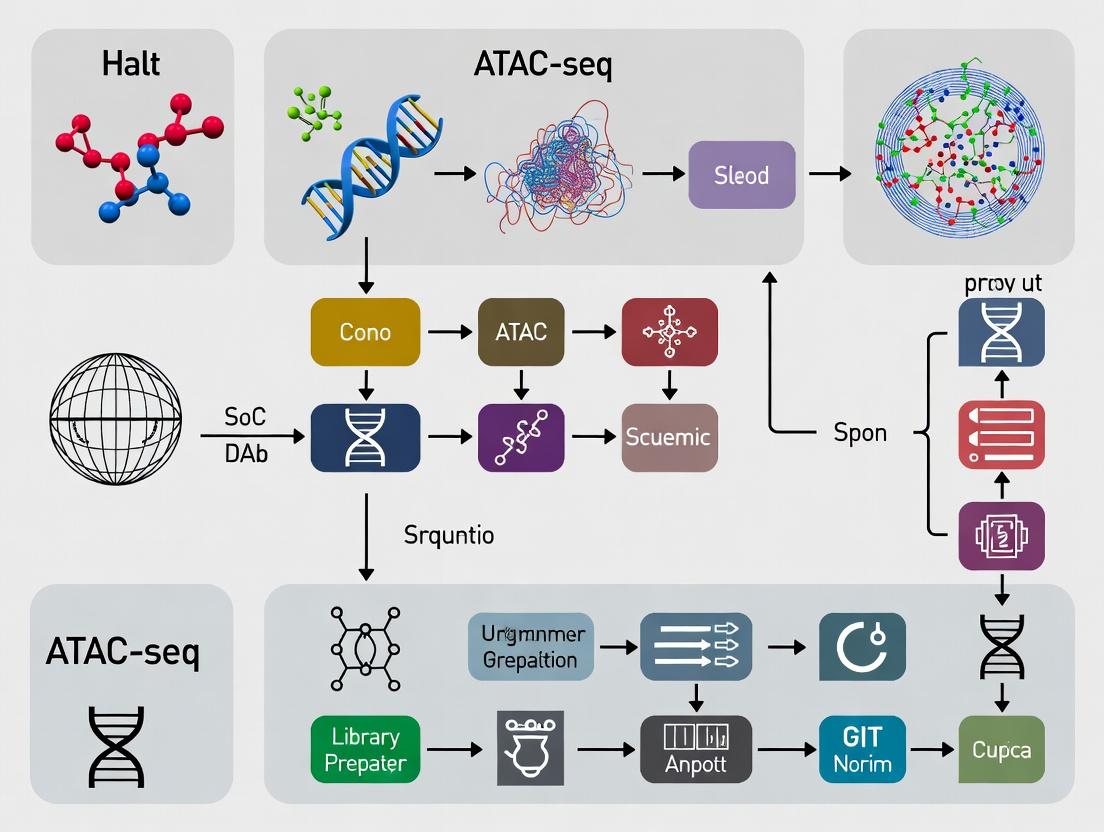
From Raw Reads to Biological Insight: A Complete Protocol for ATAC-seq Data Processing and Analysis
This article provides a comprehensive, step-by-step protocol for the processing and analysis of Assay for Transposase-Accessible Chromatin using sequencing (ATAC-seq) data, tailored for researchers and bioinformaticians.
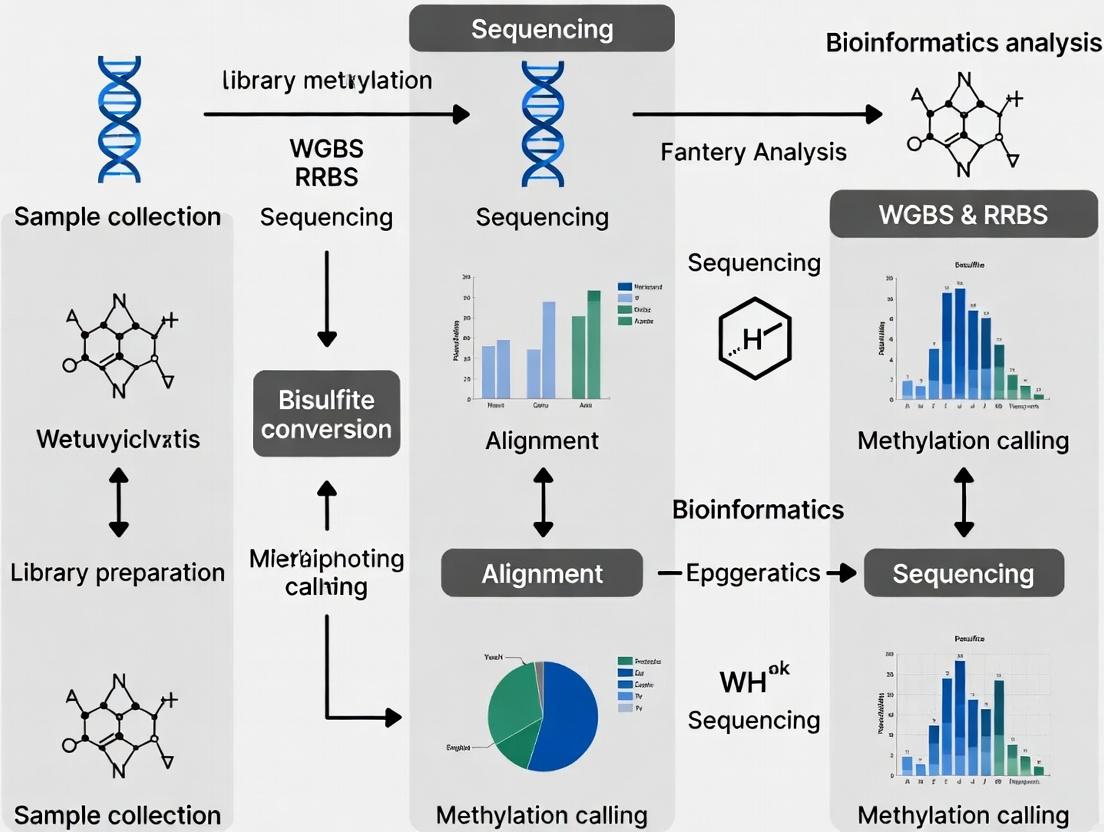
From Raw Reads to Biomarkers: A Practical Guide to WGBS and RRBS Methylation Data Analysis for Clinical and Research Applications
This article provides a comprehensive, step-by-step guide to analyzing DNA methylation data from Whole-Genome Bisulfite Sequencing (WGBS) and Reduced Representation Bisulfite Sequencing (RRBS).
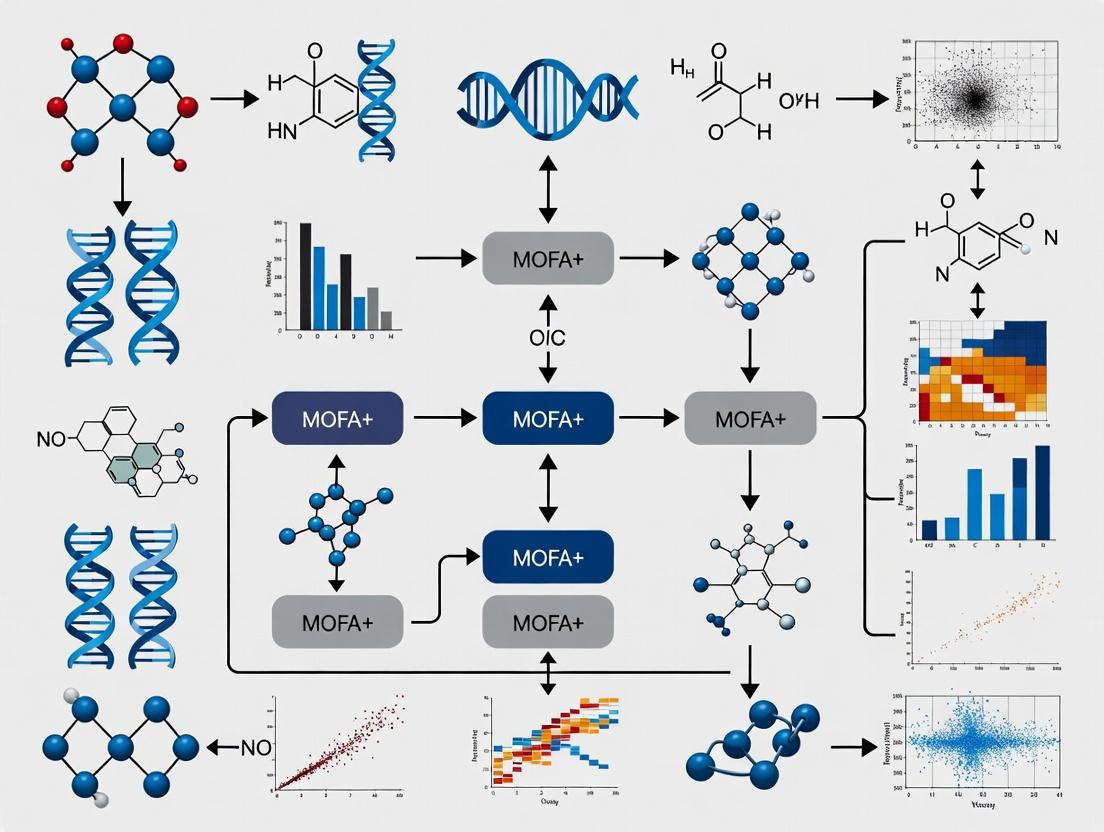
MOFA+ for Multi-Omics Integration in Cancer Research: A Statistical Framework for Unifying Biological Complexity
This article provides a comprehensive guide to Multi-Omics Factor Analysis v2 (MOFA+), a powerful statistical framework for integrating diverse molecular data in cancer research.
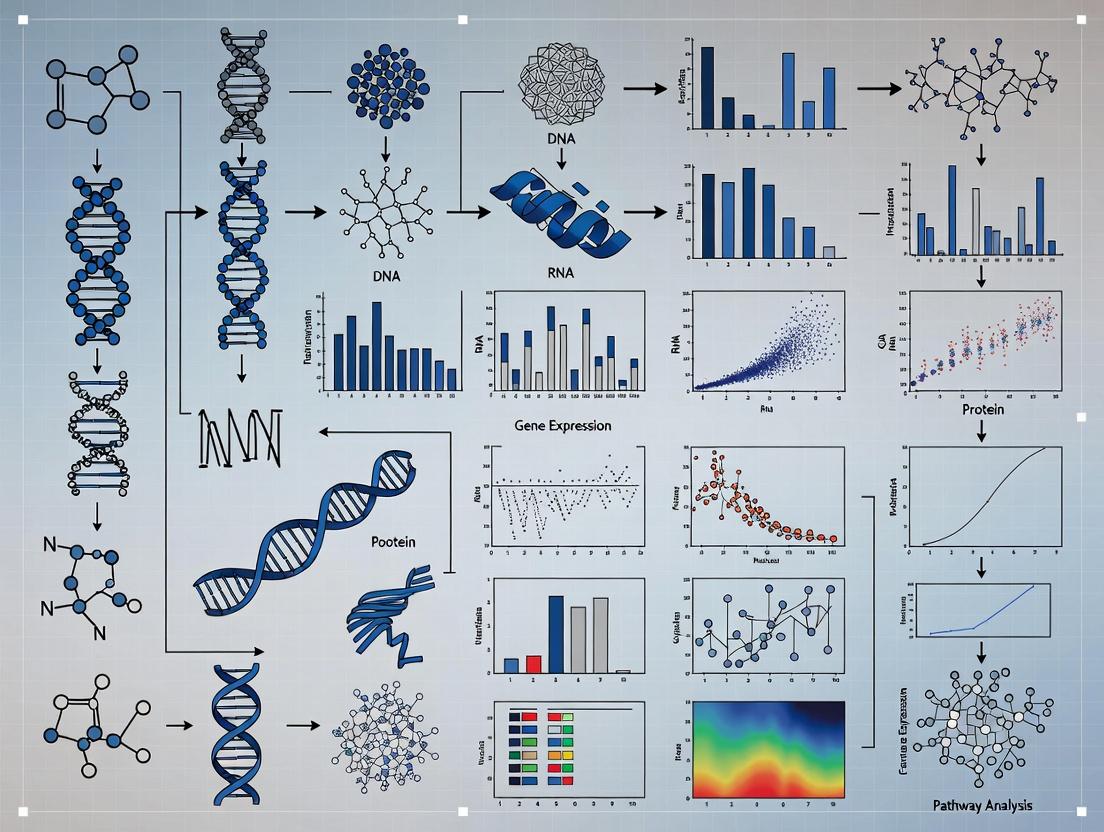
Integrating Multi-Omics with AI: Unlocking Precision Subtypes for Breast Cancer Prognosis and Therapy
This article provides a comprehensive guide for researchers and drug development professionals on multi-omics integration for breast cancer subtyping.
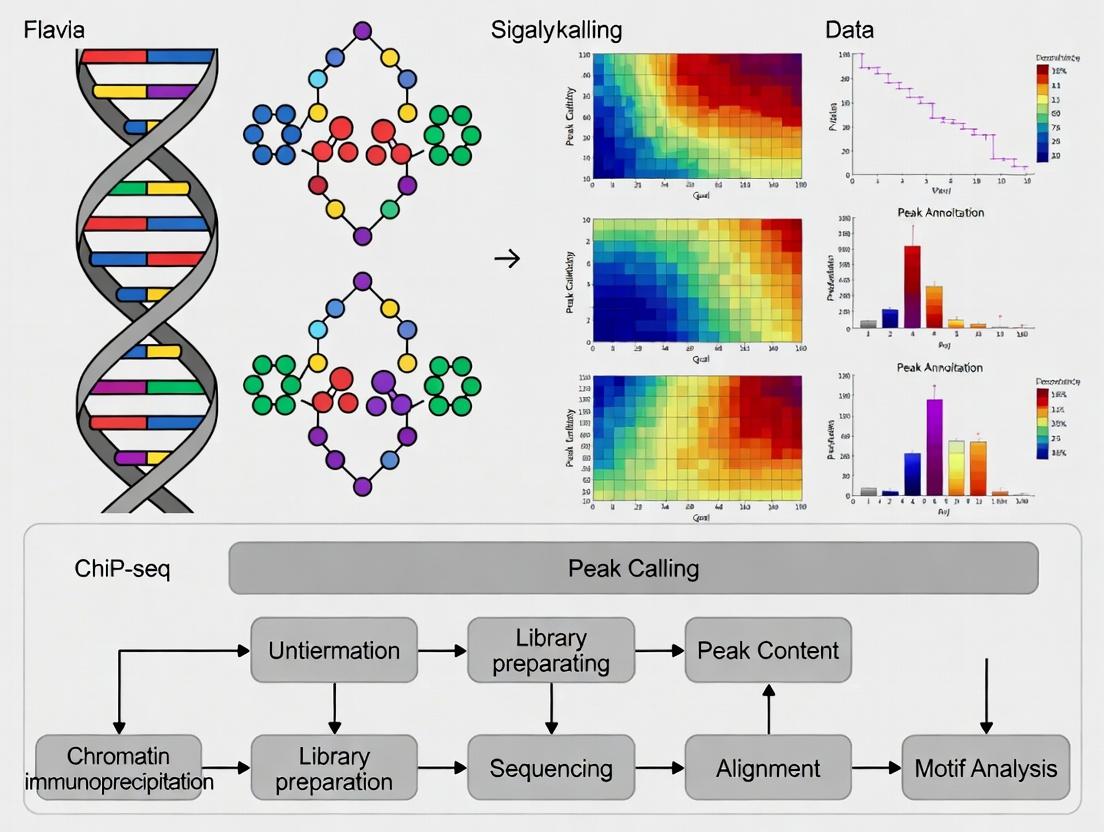
ChIP-Seq for Transcription Factor Binding Sites: From Foundational Analysis to Advanced Applications in Biomedical Research
This article provides a comprehensive guide to transcription factor binding site analysis using ChIP-seq, tailored for researchers and drug development professionals.